機械学習のアルゴリズムは大きく分けて、教師付き学習、半教師付き学習、教師なし学習、強化学習に大別できます。本ドキュメントでは、機械学習のアルゴリズムを大別する方法について説明します。機械学習は、データからパターンを学習し、予測や意思決定を行うための技術であり、そのアルゴリズムは主に四つのカテゴリに分類されます。それぞれのカテゴリには独自の特性と適用範囲があり、理解することで適切なアルゴリズムを選択する手助けとなります。
教師付き学習
教師付き学習は、入力データとそれに対応する正解ラベルが与えられる学習方法です。このアルゴリズムは、与えられたデータを基にモデルを訓練し、新しいデータに対して予測を行います。代表的なアルゴリズムには、線形回帰、ロジスティック回帰、サポートベクターマシン(SVM)、決定木、ランダムフォレスト、ニューラルネットワークなどがあります。
半教師付き学習
半教師付き学習は、教師付き学習と教師なし学習の中間に位置する手法です。少量のラベル付きデータと大量のラベルなしデータを使用してモデルを訓練します。このアプローチは、ラベル付けが困難または高コストな場合に特に有効です。半教師付き学習は、データの構造を利用して、ラベルなしデータからも情報を引き出すことができます。
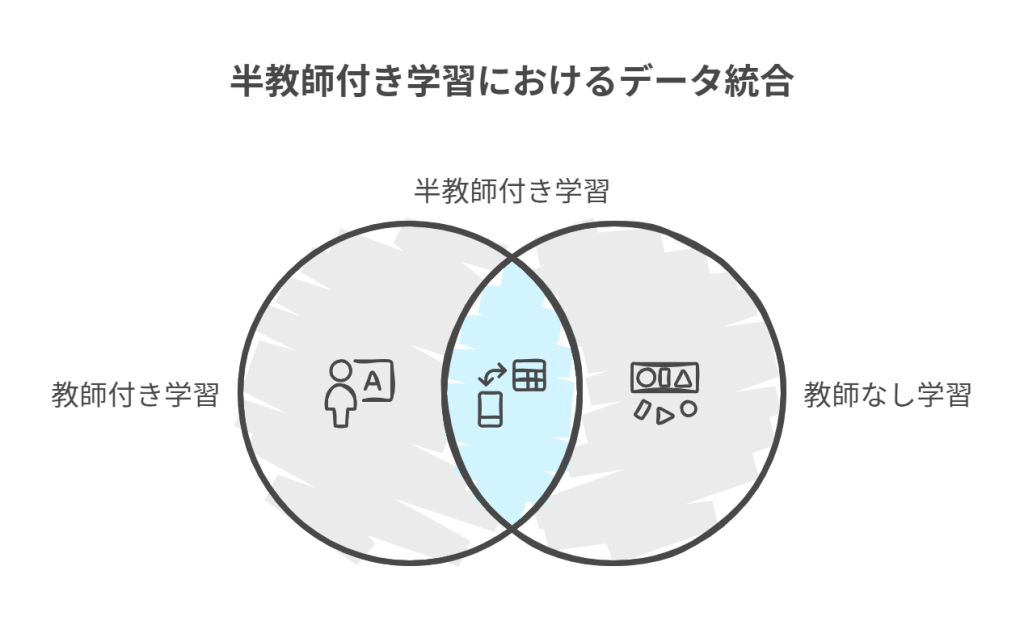
半教師付き学習は大量のデータがあり、教師がついているデータと教師がついていないデータが混在している場合に有効です。例えば、医療データなどで診断自体を下すのが大変な場合、すべてのデータに教師をつけるのは現実的ではありません。しかし、データはあるのでそれをモデルに組み込めないかというのは当然の要求です。
半教師付き学習の例
1. 医療画像の分類
医療データでは、すべての画像に対して専門家によるラベル付けが非常に時間とコストがかかるため、半教師付き学習が有効です。例えば、X線画像の診断において、一部の画像に対して専門家が疾患の有無をラベル付けし、残りの多数の画像はラベルなしで使用します。半教師付き学習は、この少量のラベル付きデータを利用して、ラベルなしデータからも学習し、疾患の有無を分類するモデルを構築します。
2. スパムメールの検出
メールフィルターの構築では、ユーザーがスパムと判断したメールは少量ですが、多くのラベルなしメールデータがあります。半教師付き学習を使用して、少量のスパムラベル付きメールと大量のラベルなしメールデータを組み合わせ、スパム検出モデルを訓練することが可能です。
3. 商品レビューの感情分析
Eコマースの分野では、商品レビューの感情分析に半教師付き学習が利用されます。一部のレビューに対してポジティブ・ネガティブのラベルを付け、そのラベル付きデータと大量のラベルなしレビューを用いて感情分析モデルを構築します。これにより、すべてのレビューを自動的に分析し、顧客満足度を評価することができます
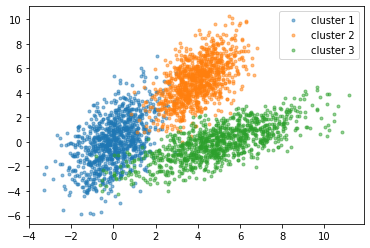
教師なし学習
教師なし学習は、ラベルなしのデータを用いてデータの構造やパターンを発見する手法です。このアルゴリズムは、クラスタリングや次元削減などのタスクに使用されます。代表的なアルゴリズムには、k-meansクラスタリング、階層的クラスタリング、主成分分析(PCA)、t-SNEなどがあります。
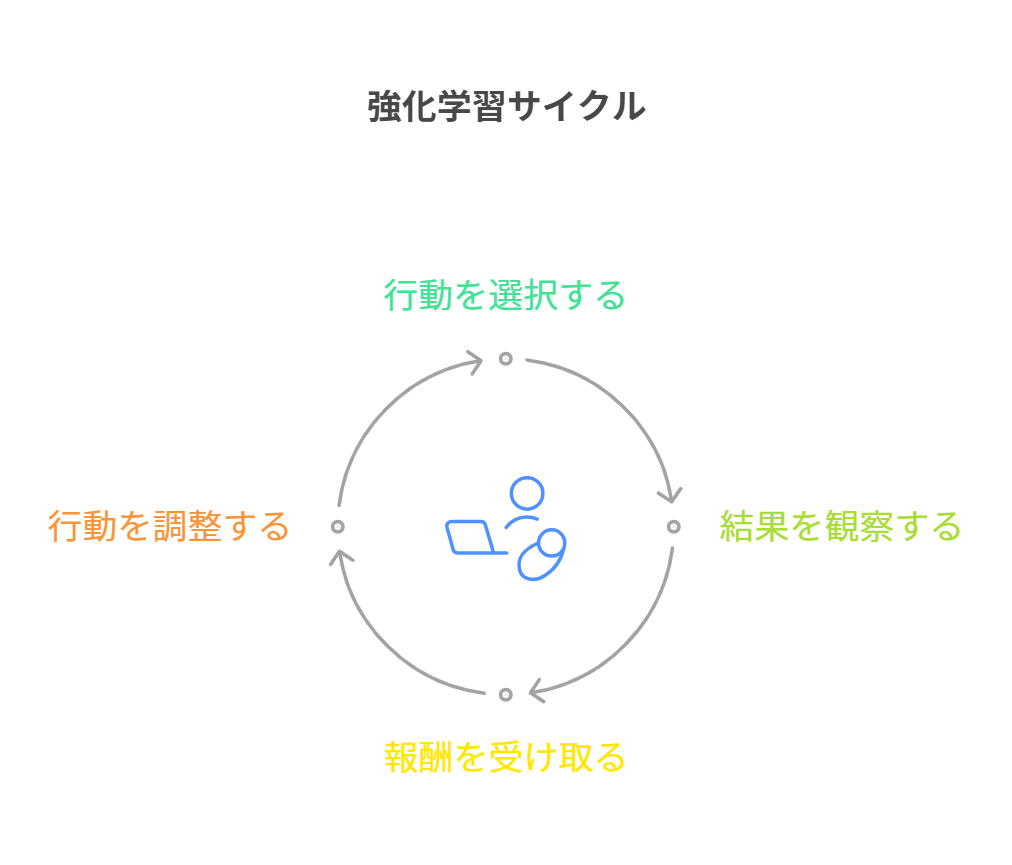
強化学習
強化学習は、エージェントが環境と相互作用しながら最適な行動を学習する手法です。エージェントは、行動を選択し、その結果に基づいて報酬を受け取ります。報酬を最大化するために、エージェントは試行錯誤を通じて学習を進めます。強化学習は、ゲームプレイやロボット制御、自動運転車などの分野で広く応用されています。